Tejas Gokhale
Assistant Professor
Computer Science & Electrical Engineering
University of Maryland, Baltimore County
Director
Cognitive Vision Group
Affiliate Faculty
UMBC Center for AI
Faculty Affiliate
UMBC Public Health Research Center
Host, PPR Seminar
Teaching
CMSC 472/672 Computer Vision [F25]
CMSC 475/675 Neural Networks [S26, S25]
CMSC 491/691 Robust Machine Learning [F24]
CMSC 491/691 Computer Vision [S24, F23]
Office Hours
W 1430--1530; ITE 342-B
I'm a
philosopher,
artist,
scientist, and
professor
of
computing.
[Click or hover on underlined words to learn what they mean].
I ask and grapple with questions in computational perception, learning, reasoning, and communication.
My research lab, the Cognitive Vision Group at UMBC, works on research themes such as:
concept-level characterization of the visual world;
the interpretation of visual data in presence of incomplete information;
recognizing and adapting to novelty and variations;
leveraging external knowledge and reasoning modules to generalize to new contexts, domains, environments, and tasks;
acquiring visual knowledge and communicating it to other machines and humans.
I received my Ph.D. from Arizona State University, my M.S. from Carnegie Mellon University, and my B.E. (Honours) degree from Birla Institute of Technology and Science, Pilani.
I run the Perception, Prediction, and Reasoning Seminar at UMBC.
If you're interested in working with CVG
please read this document
and use this form.
Note: I'm not looking for new Ph.D. students at this time.

News
| JUN 2026 | Participating in the Sustainable Research Pathways program (with Sourajit and Naren). Thank you Sustainable Horizons Institute! |
| MAR 2026 | Tejas' Talk Tour: -- Keynote @ WACV EVGEN Workshop; -- Invited Talk @ LLNL; -- Invited Talk @ Amazon Science |
| OCT 2025 | Spotlight talk at ICCV 2025 Area Chair Workshop |
| OCT 2025 | Serving at Tutorial Chair for ICCV 2025 |
| JUN 2025 | Vocalist for CVPR House Band, Music City Center, Nashville |
| JAN 2025 | Received CIDER funding (with GESTAR-II) from UMBC ORD |
| JAN 2025 | Received funding from UMBC Cybersecurity Institute |
| DEC 2024 | Co-PI for a grant from the DARPA SciFy program. |
| OCT 2024 | My alma mater ASU wrote a profile feature about me. |
Tutorials:
Responsibly Building Generative Models [RBGM @ECCV 2024]
Reliability of Generative Models in Vision [RGMV @WACV 2024]
Semantic Data Engineering for Robustness under Multimodal Settings [SERUM @WACV 2023]
Publications

Sarah Rastegar, Violeta Chatalbasheva, Sieger Falkena, Anuj Singh, Yanbo Wang, Tejas Gokhale, Hamid Palangi, Hadi Jamali-Rad
pdf code
InfSplign is a training-free inference-time method that improves spatial alignment in text-to-image generation by adjusting the noise through a compound loss in every denoising step. The proposed compound loss is comprised of three components: an object location loss that enforces accurate spatial grounding, an object presence loss, which increases the certainty of object representation, and an object balance loss, which mitigates cross-object interference in the finer layers of the U-Net decoder. The approach results in more accurate object placement and a balanced object presence during sampling.
Shaswati Saha, Sourajit Saha, Manas Gaur, Tejas Gokhale,
pdf code
Concerns about text-to-image (T2I) generative models infringing on privacy, copyright, and safety have led to the development of Concept Erasure Techniques (CETs). The goal of an effective CET is to prohibit the generation of undesired ``target'' concepts specified by the user, while preserving the ability to synthesize high-quality images of the remaining concepts. In this work, we demonstrate that (1) CETs can be easily circumvented: using superclass-subclass hierarchy, semantically similar prompts such as compositional variants of the target; and (2) CETs suffer from several side-effects such as attribute leakage and counterintuitive phenomena of attention concentration or dispersal.

Naresh Kumar Devulapally, Shruti Agarwal, Tejas Gokhale, Vishnu Suresh Lokhande
The effectiveness of personalization techniques in text-to-image generaiton has lead to concerns regarding data privacy, intellectual property protection, and unauthorized usage. We present a model-based perturbation strategy that is resistant to inversion and personalization while ensuring that the perturbed images maintain high visual fidelity to the original inputs. This approach integrates unlearnability into the framework of Latent Diffusion Models, alternating between denoising and inversion while modifying the starting point of the denoising trajectory of diffusion models.

Nilay Yilmaz, Maitreya Patel, Yiran Luo, Tejas Gokhale, Chitta Baral, Suren Jayasuriya, Yezhou Yang
pdf code data
VOILA, a large-scale, open-ended, dynamic benchmark designed to evaluate MLLMs’ perceptual understanding and abstract relational reasoning. VOILA employs an analogical mapping approach in the visual domain, requiring models to generate an image that completes an analogy between two given image pairs, reference and application, without relying on predefined choices.
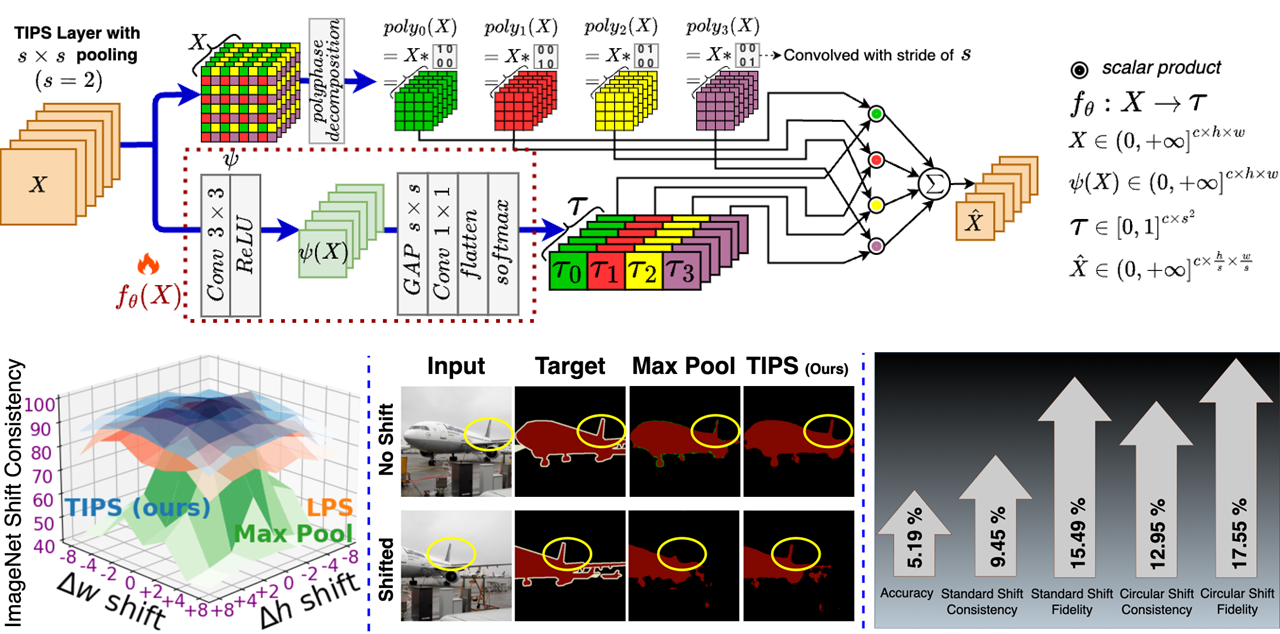
Sourajit Saha, Tejas Gokhale
pdf code
We identify that the tendency of existing pooling layers in CNNs to pass larger signals to subsequent layers is a major factor that's strongly correlated with the lack of shift invariance in CNNs. Based on this finding, we design a new pooling operator Translation-Invariant Polyphase Sampling (TIPS) and two regularizations on the intermediate feature maps to learn translation-invariant representations. TIPS results in consistent and architecture-agnostic improvements in accuracy and four measures of shift invariance, across multiple image classification and segmentation benchmarks.
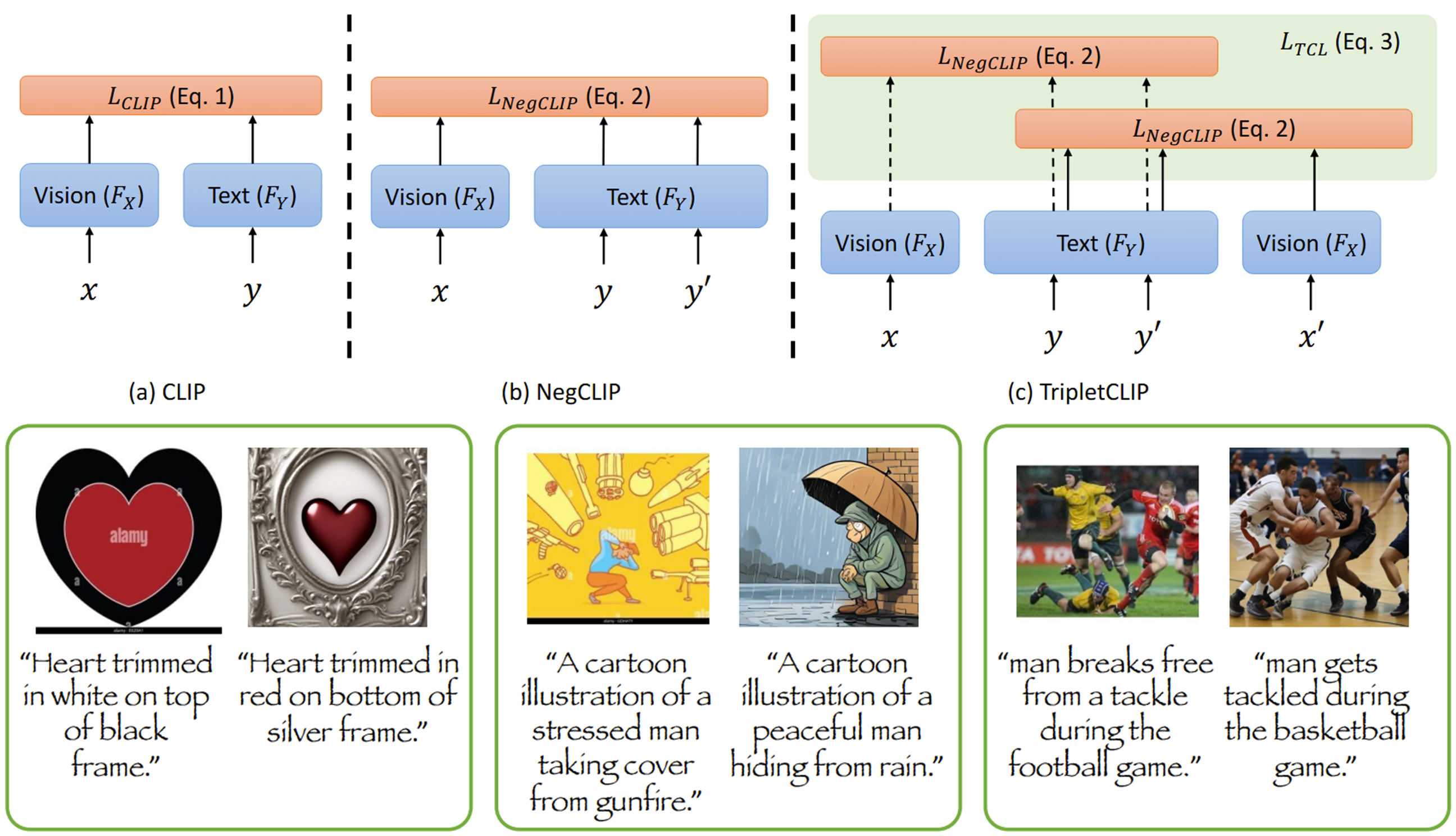
Maitreya Patel, Abhiram Kusumba, Sheng Cheng, Changhoon Kim, Tejas Gokhale, Chitta Baral, Yezhou Yang
pdf web code data
A method for generating ``hard'' negative captions via in-context learning and synthesizing corresponding negative images with text-to-image generators. A novel contrastive pre-training strategy that leverages these hard negative captions and images in an alternating fashion to train CLIP. Our method "TripletCLIP" enhances the compositional capabilities of CLIP as well as improvements in zero-shot image classification and image retrieval.
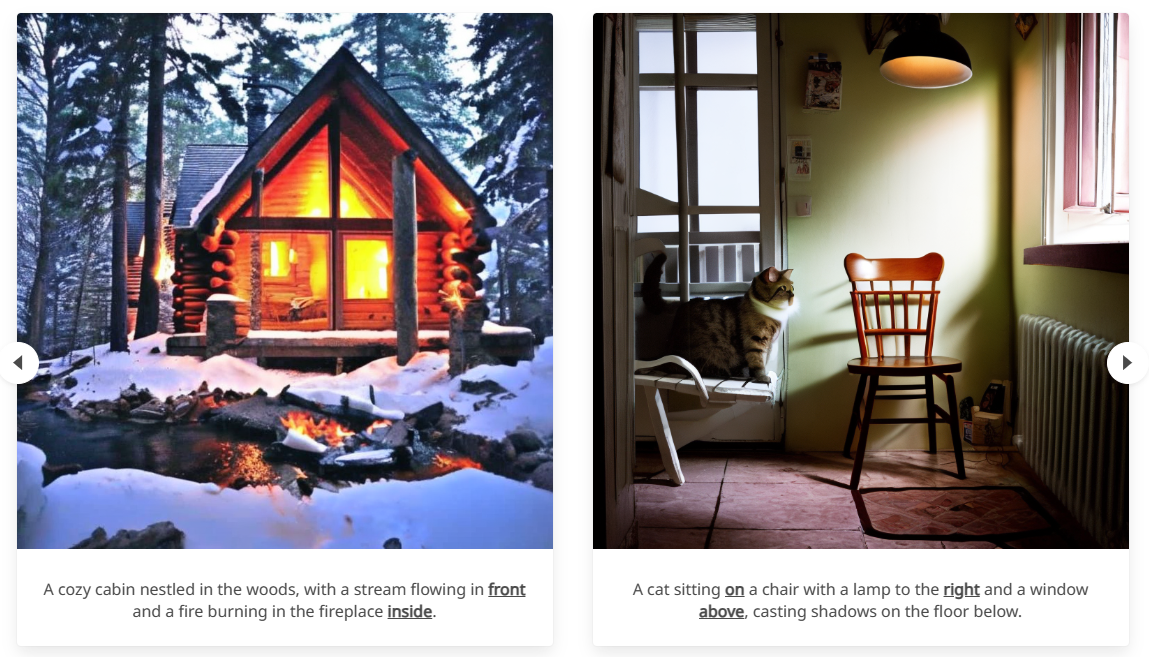
Agneet Chatterjee, Gabriela Ben Melech Stan, Estelle Aflalo, Sayak Paul, Dhruba Ghosh, Tejas Gokhale, Ludwig Schmidt, Hannaneh Hajishirzi, Vasudev Lal, Chitta Baral, Yezhou Yang
pdf web code demo
We improve spatial understanding of T2I models by creating the SPRIGHT dataset by recaptioning 6M images from widely used vision datasets. Finetuning T2I models with just 500 images from SPRIGHT leads to a large improvement in T2I spatial understanding performance, across several evaluation benchmarks such as T2I-CompBench, VISOR, and GenEval.
Agneet Chatterjee, Yiran Luo, Tejas Gokhale, Chitta Baral, Yezhou Yang
pdf web code data
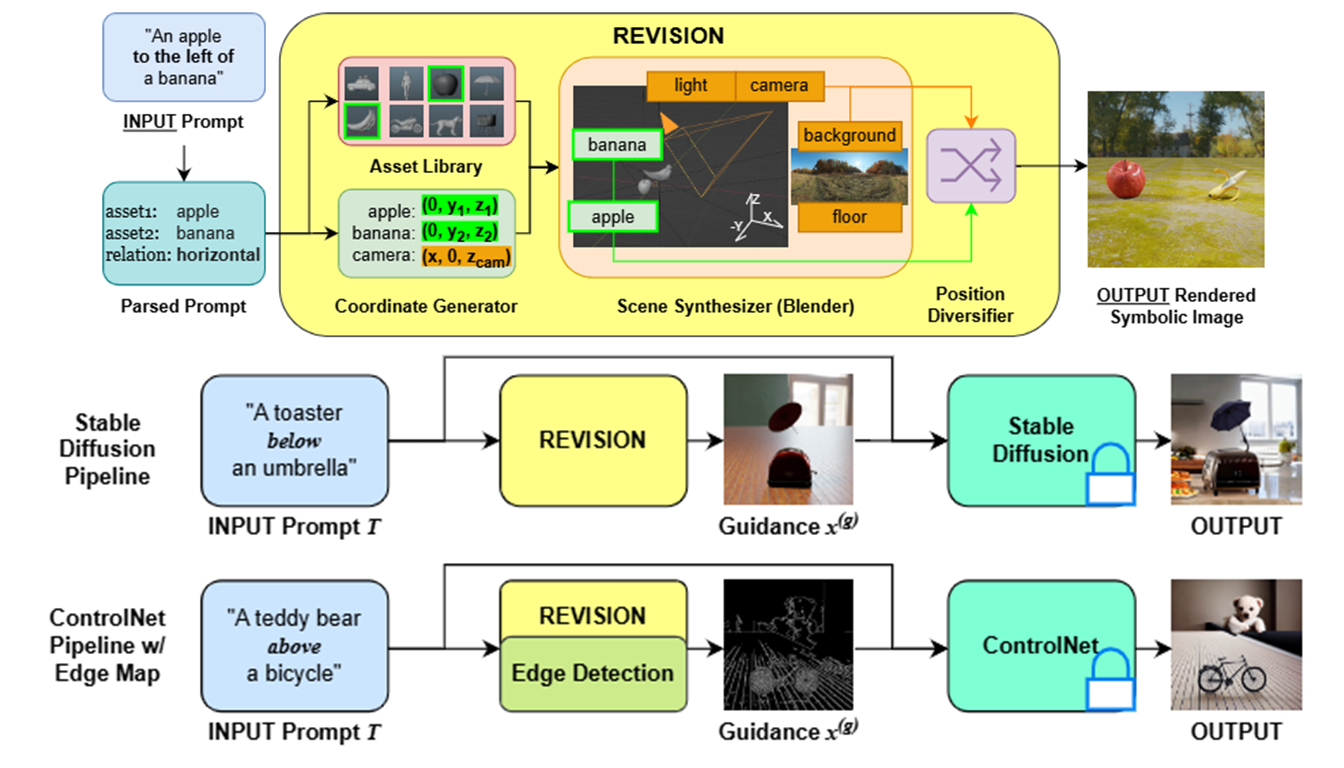
Traditional generative Text-to-Image models struggle to generate images that faithfully represent the spatial relationships mentioned in the input prompt. We develop REVISION, an efficient rendering pipeline that enables a training-free, guidance-based mechanism to address this shortcoming. REVISION takes the objects and their spatial relationships parsed from the given input prompt and synthesizes an image in Blender, placing the respective object assets at coordinates corresponding to the parsed spatial relationship. Given a user-provided input prompt T, we synthesize an image using REVISION and use it to guide existing T2I pipelines such as Stable Diffusion or ControlNet to obtain a spatially accurate output.
Agneet Chatterjee, Tejas Gokhale, Chitta Baral, Yezhou Yang
pdf web code
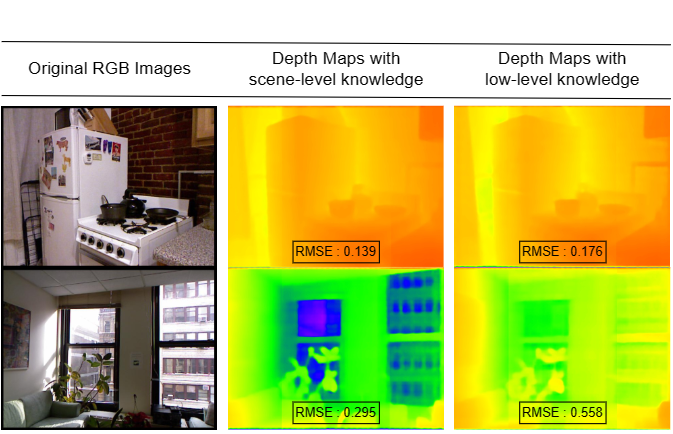
The motivation of this work is to analyze the efficacy of language guidance for low-level non-semantic computer vision tasks. We focus on depth estimation and find that language-guided depth estimators benefit only from scene-level language information and counter-intuitively, are worse off when presented with sentences that describe 3D spatial relationships in the scene. With an increasing number of methods using language for depth estimation, our findings highlight the opportunities and pitfalls that require careful consideration for effective deployment in real-world settings.

Yiran Luo, Joshua Feinglass, Tejas Gokhale, Kuan-Cheng Lee, Chitta Baral, Yezhou Yang
pdf code data [Best Paper Award]
Two new quantitative measures ICV and IDD to describe domain shifts in terms of consistency of classes within one domain and similarity between two stylistic domains. New dataset: SuperMarioDomains (SMD) incorporating unique features of consistent classes of video game scenes across stylistic domains in video game graphics that are dissimilar to ImageNet1K.
Maitreya Patel, Tejas Gokhale, Chitta Baral, Yezhou Yang
pdf web code
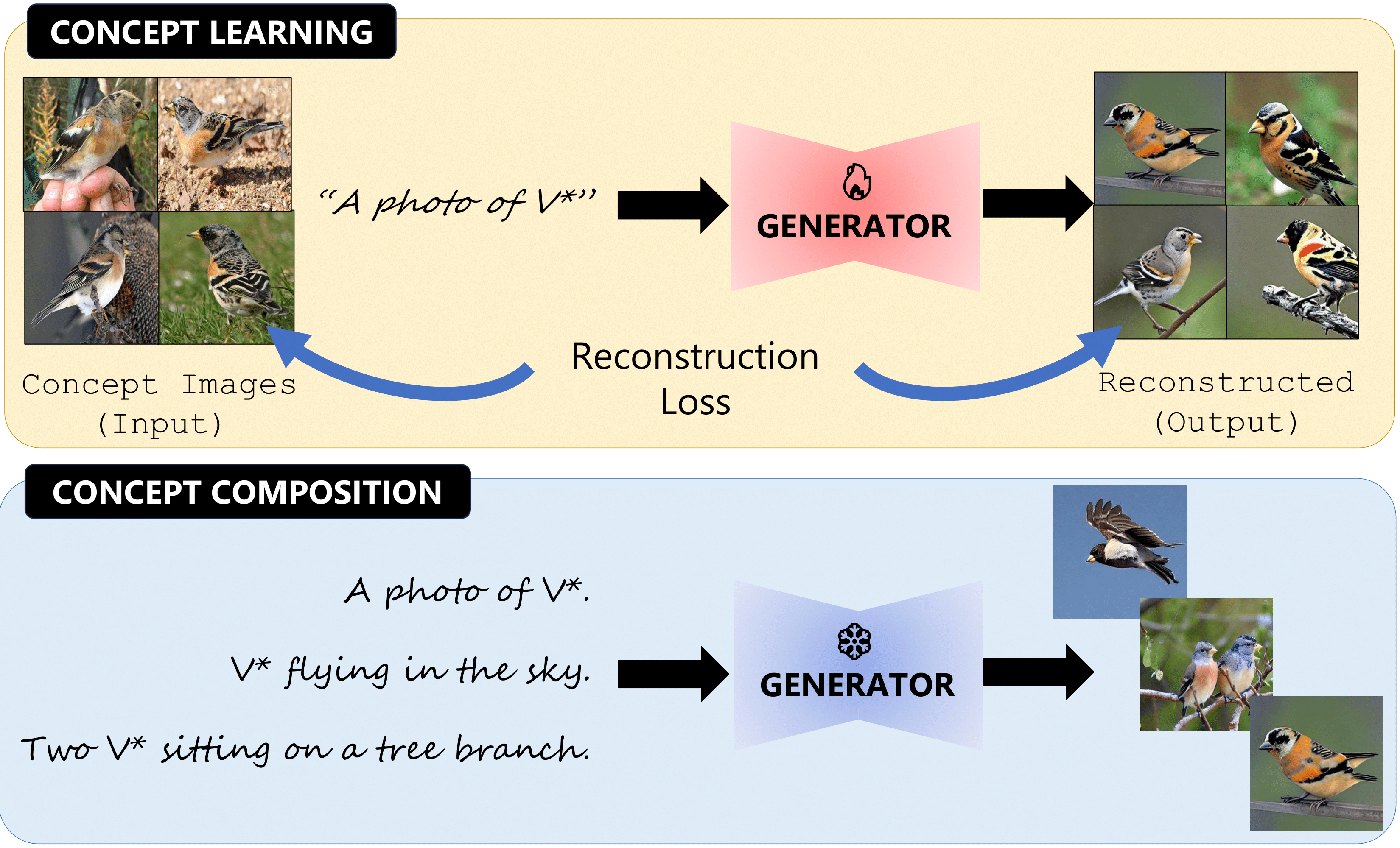
Textual inversion models have the potential to learn novel concepts from a small number of example images. We quantify this concept learning ability with ConceptBed: a dataset that contains 284 unique visual concepts and 33K concept compositions, and CCD (Concept Confidence Deviation): an evaluation metric uses the confidence of oracle concept classifiers to measure the alignment between generated images and concepts contained in ground truth images.
Sheng Cheng, Tejas Gokhale, Yezhou Yang
pdf code
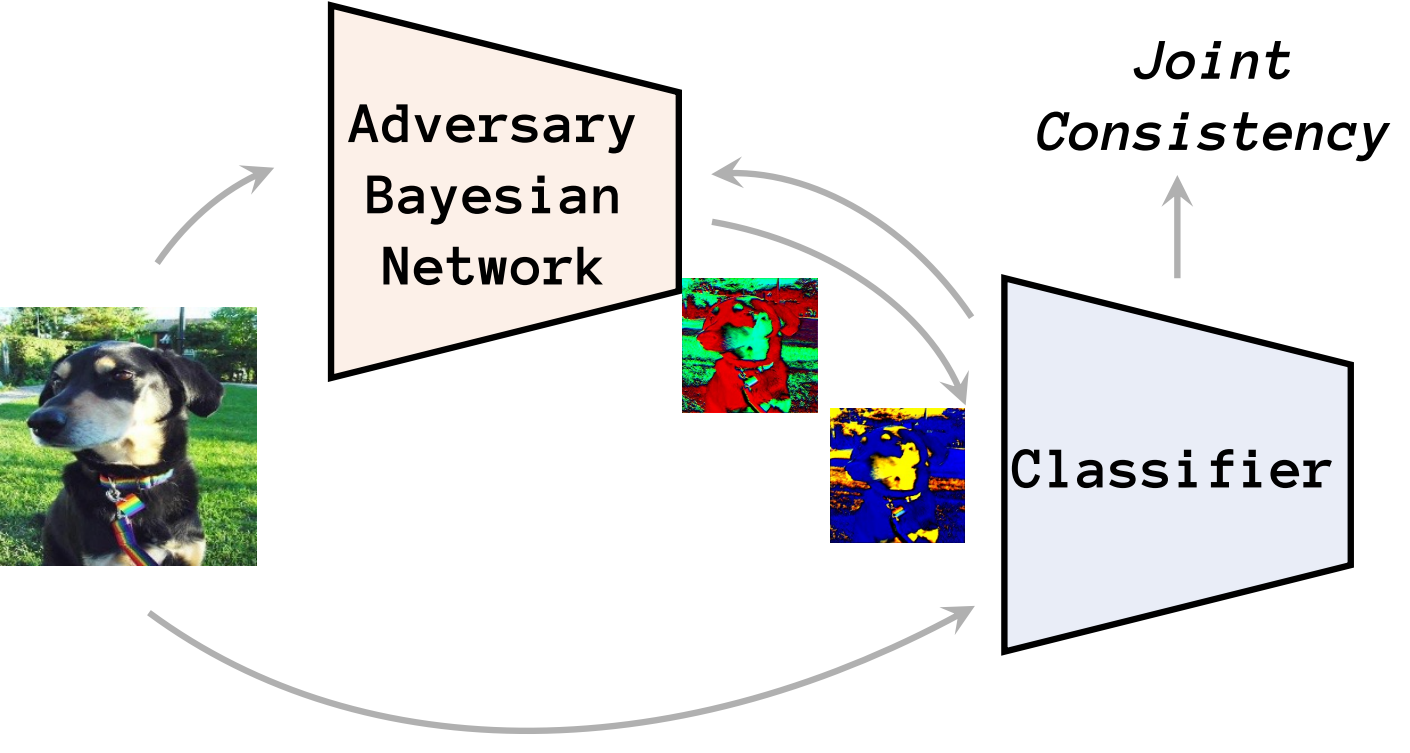
ABA draws on the strengths of adversarial learning and Bayesian neural networks to guide the generation of diverse data augmentations — these synthesized image domains aid the classifier in generalizing to several types of domain shift including style shift, subpopulation shift, and domain shift in the medical imaging setting. ABA outperforms all previous state-of-the-art methods, including pre-specified augmentations, pixel-based and convolutional-based augmentations.
Tejas Gokhale
This dissertation contributes to the reliability of machine learning models from several perspectives including the development of robust training algorithms to mitigate the risks of such failures, construction of new datasets that provide a new perspective on capabilities of vision models, and the design of evaluation metrics for re-calibrating the perception of performance improvements.
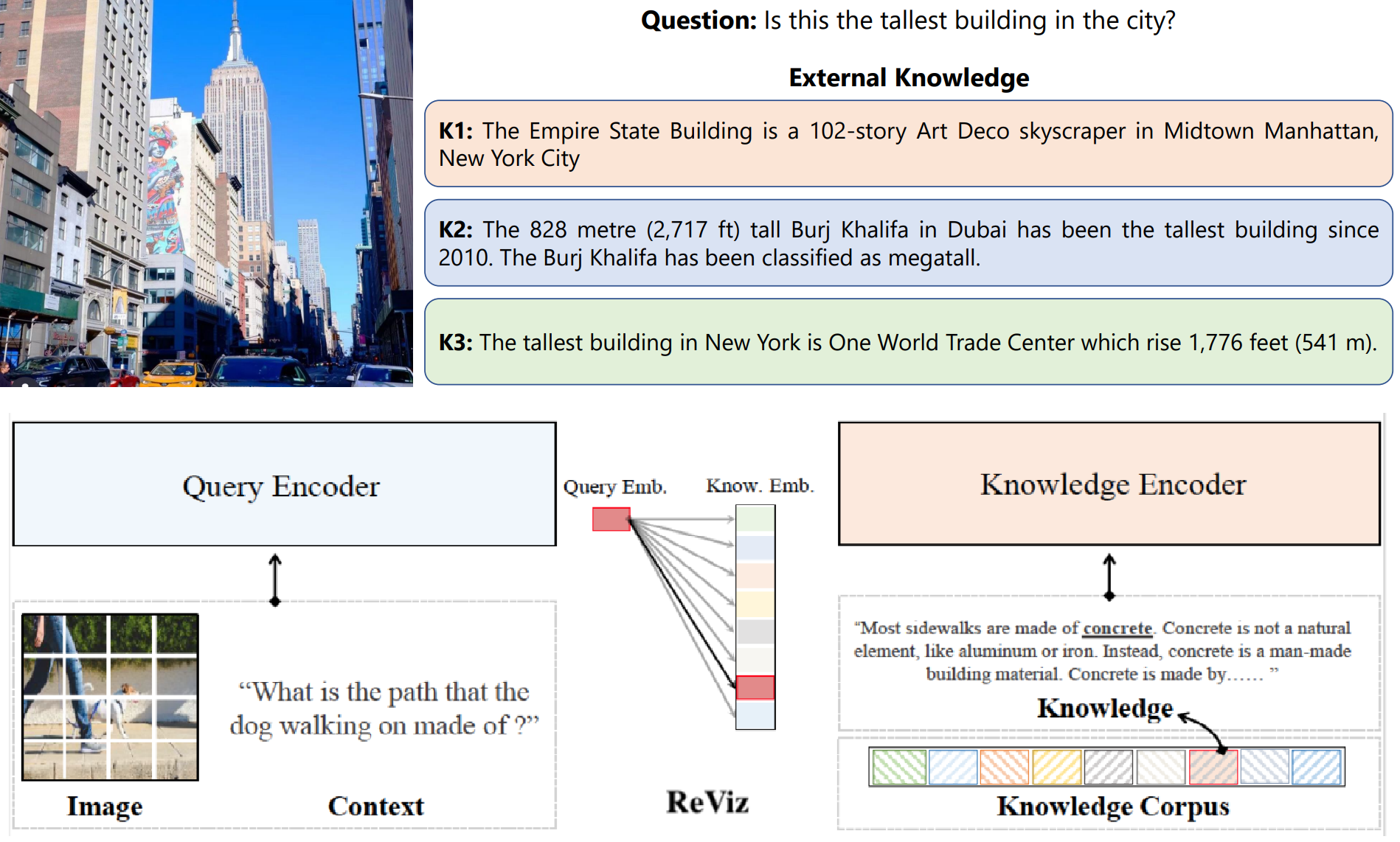
Man Luo, Zhiyuan Fang, Tejas Gokhale, Yezhou Yang, Chitta Baral
pdf data
Knowledge retrieval with multi-modal queries, i.e., queries containing information split across image and text inputs, a challenging task that differs from previous work on cross-modal retrieval. A new dataset called ReMuQ, a new pretraining task for learning knowledge retrieval with multimodal queries, and a retriever model "ReViz" that can directly process input text and images to retrieve relevant knowledge in an end-to-end fashion without being dependent on intermediate modules such as object detectors or caption generators.
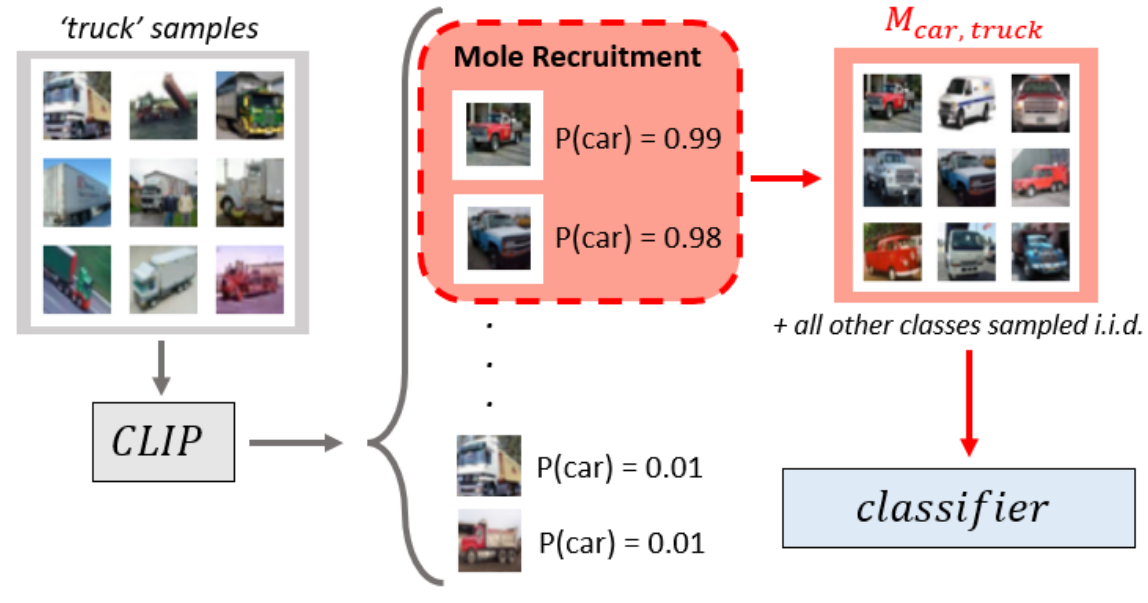
Ethan Wisdom, Tejas Gokhale, Yezhou Yang
pdf code
A data poisoning attack that confounds ML models without any manipulation of the image or label, achieved by simply leveraging the most confounding natural samples found within the training data itself. We show the efficacy of this novel attack in offline as well as continual learning (CL) settings in image classification, thereby exposing a previously undetected vulnerability of image classifiers.

Tejas Gokhale, Hamid Palangi, Besmira Nushi, Vibhav Vineet, Eric Horvitz, Ece Kamar, Chitta Baral, Yezhou Yang
pdf web code [featured on MSR blog]
We report a surprising finding that, although recent state-of-the-art T2I models exhibit high image quality, they are severely limited in their ability to generate multiple objects or the specified spatial relations such as left/right/above/below. We introduce a metric called VISOR to quantify spatial reasoning performance. VISOR can be used off-the-shelf with any text-to-image model. We construct and make available SR2D, a dataset which contains sentences that describe spatial relationships (left/right/above/below) between a pair of commonly occurring objects.
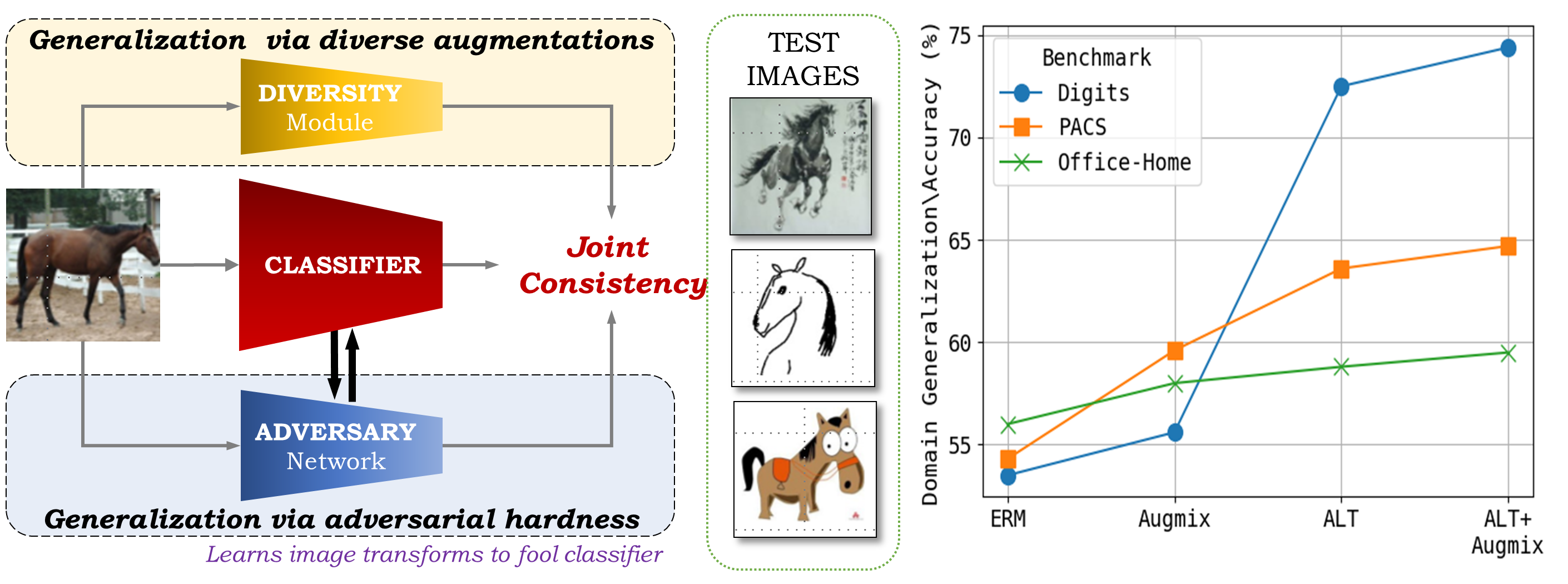
Tejas Gokhale, Rushil Anirudh, Jayaraman J. Thiagarajan, Bhavya Kailkhura, Chitta Baral, Yezhou Yang
pdf code video
ALT discovers diverse and adversarial transformations using an image-to-image neural network with learnable weights. ALT improves the state-of-the-art single domain generalization performance on three benchmarks and is significantly better than pixel-wise adversarial training and standard data augmentation techniques.

Maitreya Patel, Tejas Gokhale, Chitta Baral, Yezhou Yang
pdf web code
Although the imaging pipeline is unable to capture many physical properties of objects (eg. mass and coefficient of friction), these properties can be estimated by utilizing cues introduced by collisions. We introduce a new dataset (CRIPP-VQA) for reasoning about the implicit physical properties of objects from videos. The dataset contains videos of objects in motion, annotated with hypothetical/counterfactual questions about the effect of actions (removing/adding/replacing objects) and questions about planning (performing actions to reach a goal).
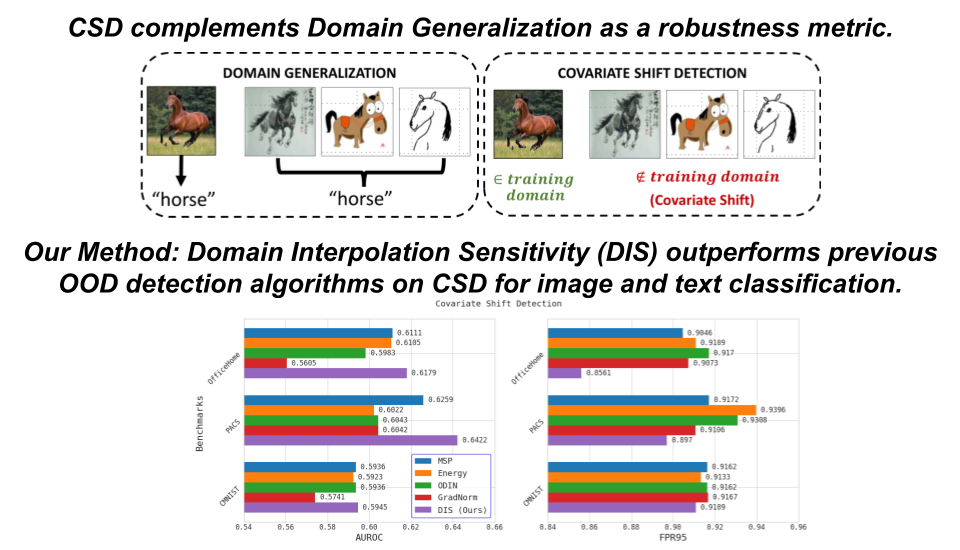
Tejas Gokhale, Joshua Feinglass, Yezhou Yang
pdf video
In this paper, we introduce a benchmark for covariate shift detection (CSD), that builds upon and complements previous work on domain generalization. We find that existing novelty detection methods designed for OOD benchmarks perform worse than simple confidence-based methods on our CSD benchmark. We propose Domain Interpolation Sensitivity (DIS), based on the simple hypothesis that interpolation between the test input and randomly sampled inputs from the training domain, offers sufficient information to distinguish between the training domain and unseen domains under covariate shift.
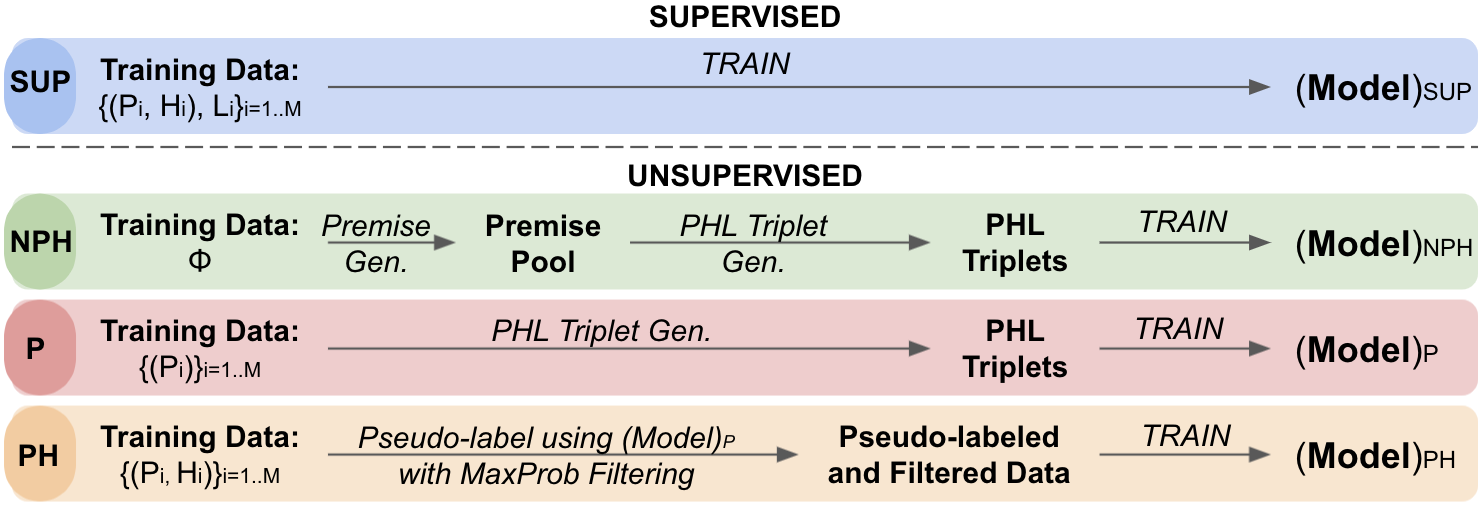
Neeraj Varshney, Pratyay Banerjee, Tejas Gokhale, Chitta Baral,
pdf code video
Natural Language Inference (NLI) under three low-data settings (with missing labels; with missing labels and hypothesis; and with missing labels, hypotheses, and premises). A procedural data generation approach that leverages a set of sentence transformations to collect PHL (Premise, Hypothesis, Label) triplets for training NLI models, bypassing the need for human-annotated training data. State-of-the-art results under all three "unsupervised" settings.

Tejas Gokhale, Abhishek Chaudhary, Pratyay Banerjee, Chitta Baral, Yezhou Yang,
pdf code video
SDRO: a distributed robust optimization method that operates with linguistic transformations of sentence inputs, SISP: a suit of semantics-inverting (SI) and semantics-preserving (SP) linguistic transformations, and an ensembling technique for vision-and-language inference.
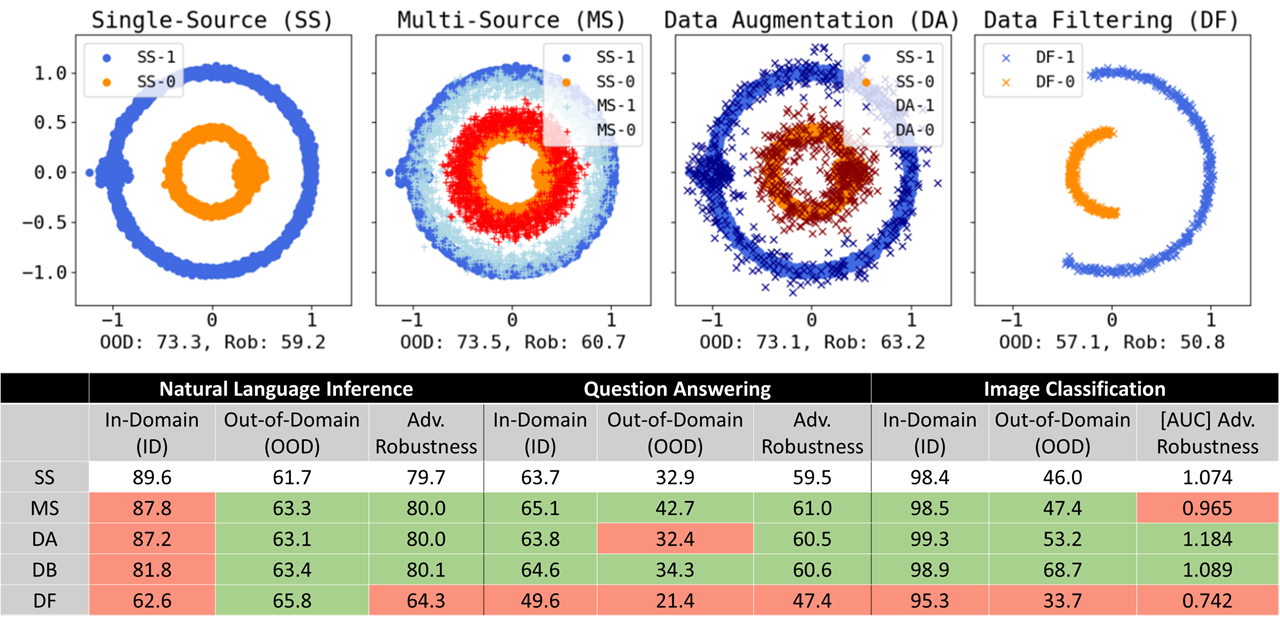
Tejas Gokhale, Man Luo, Swaroop Mishra, Bhavdeep Singh Sachdeva, Chitta Baral
pdf video
In this work, we conduct a comprehensive study of common data modification strategies and evaluate not only their in-domain and OOD performance, but also their adversarial robustness (AR). This work serves as an empirical study towards understanding the relationship between generalizing to unseen domains and defending against adversarial perturbations.

Yiran Luo, Pratyay Banerjee, Tejas Gokhale, Yezhou Yang, Chitta Baral
pdf data
We present a debiased dataset for the Person Centric Visual Grounding (PCVG) task. For instance, in many cases the first name in the sentence corresponds to the largest bounding box, or the sequence of names in the sentence corresponds to an exact left-to-right order in the image). The debiased dataset offers the PCVG task a more practical baseline for reliable benchmarking and future improvements.
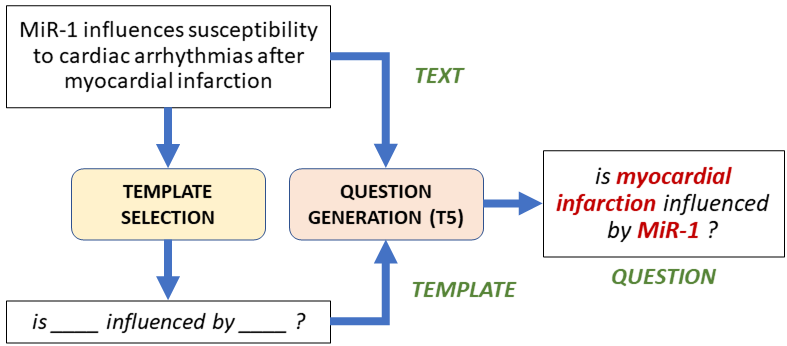
Man Luo, Arindam Mitra , Tejas Gokhale, Chitta Baral
We seek to improve information retrieval (IR) using neural retrievers (NR) in the biomedical domain, using a three-pronged approach. (1) a template-based question generation method, (2) two novel pre-training tasks that are closely aligned to the downstream task of information retrieval, (3) the ``Poly-DPR'' model which encodes each context into multiple context vectors.
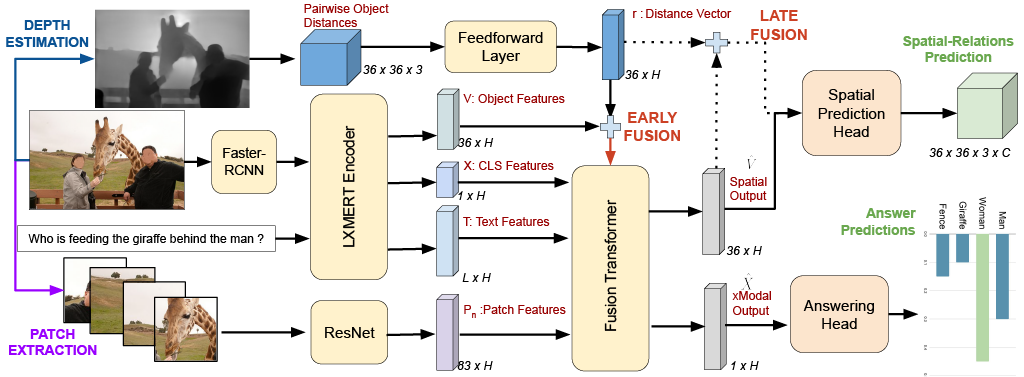
Pratyay Banerjee, Tejas Gokhale, Yezhou Yang, Chitta Baral
VQA models trained with two additional objectives: object centroid estimation and relative position estimation, lead to improved performance on spatial reasoning questions (in GQA) in fully supervised and few shot settings as well as improved O.O.D. generalization.

Pratyay Banerjee, Tejas Gokhale, Yezhou Yang, Chitta Baral
We show that models can be trained without any human-annotated Q-A pairs, but only with images and associated text captions. Our experiments suggest gains on benchmark with shifted priors (VQA-CP) over baselines which use full supervision from human-authored QA data.
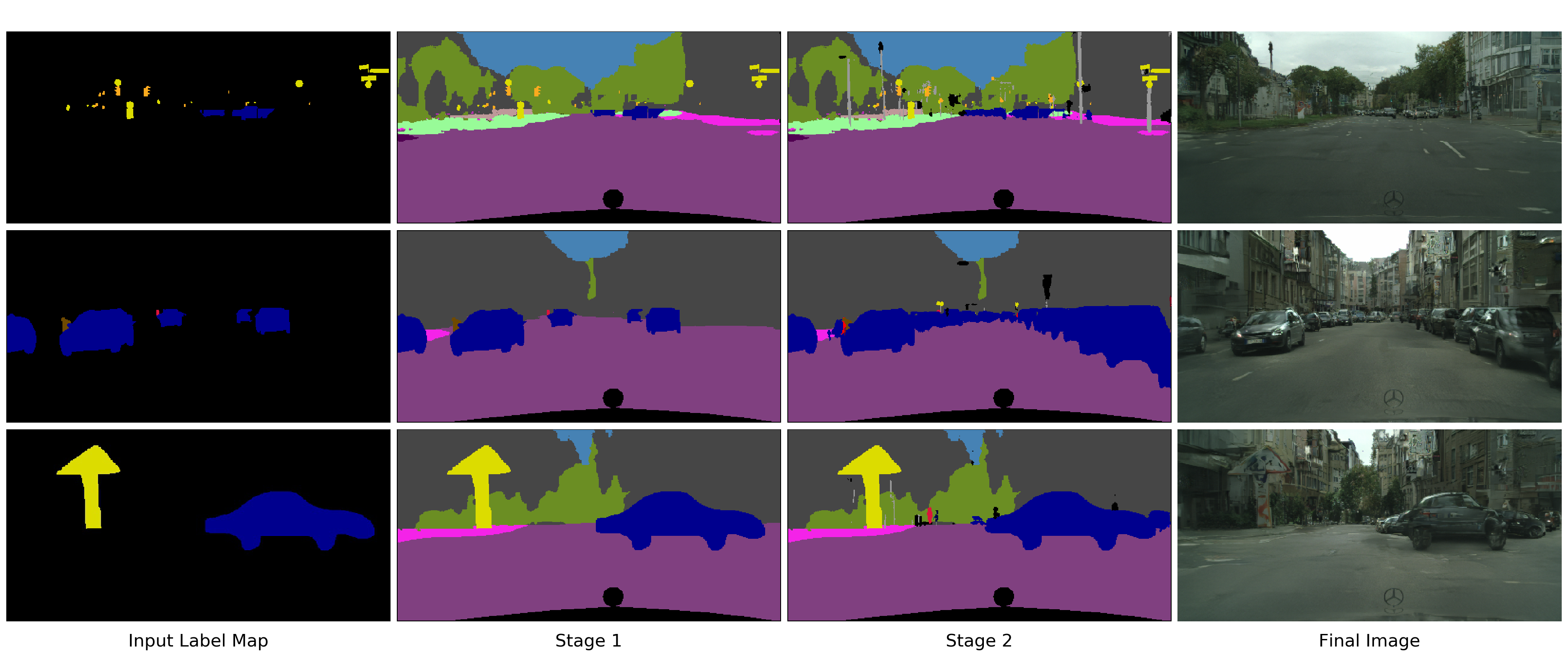
Kuldeep Kulkarni, Tejas Gokhale, Rajhans Singh, Pavan Turaga, Aswin Sankaranarayanan
Scene completion from sparse and incomplete label maps. `Halluci-Net' is a 2-stage method that captures the object co-occurrence relationships, to produce dense label maps from incomplete labelmaps and object boundaries, for image synthesis.
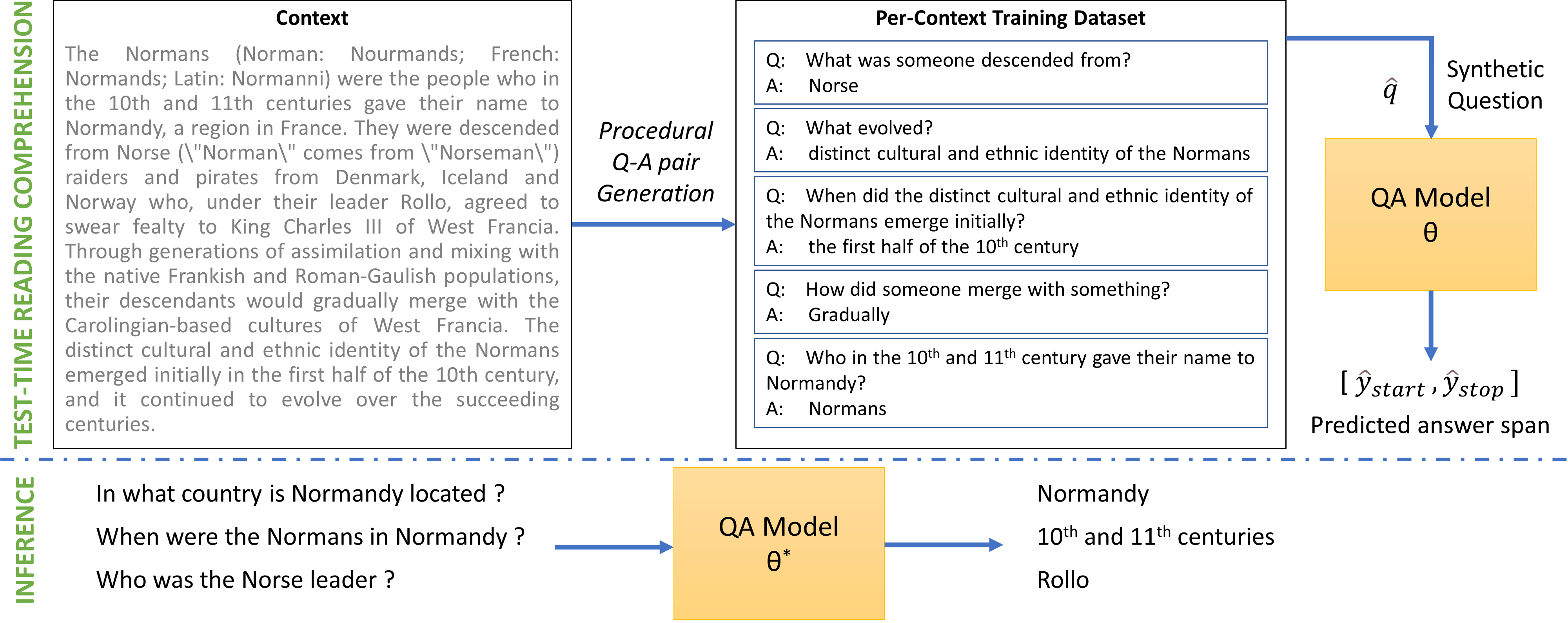
Pratyay Banerjee, Tejas Gokhale, Chitta Baral
Unsupervised Reading Comprehension method that operates directly on a single test passage. Synthetic QA pairs are generated from the passage, and models are trained on these. When a new human-authored test question appears, models infer answers better than previous unsupervised methods.
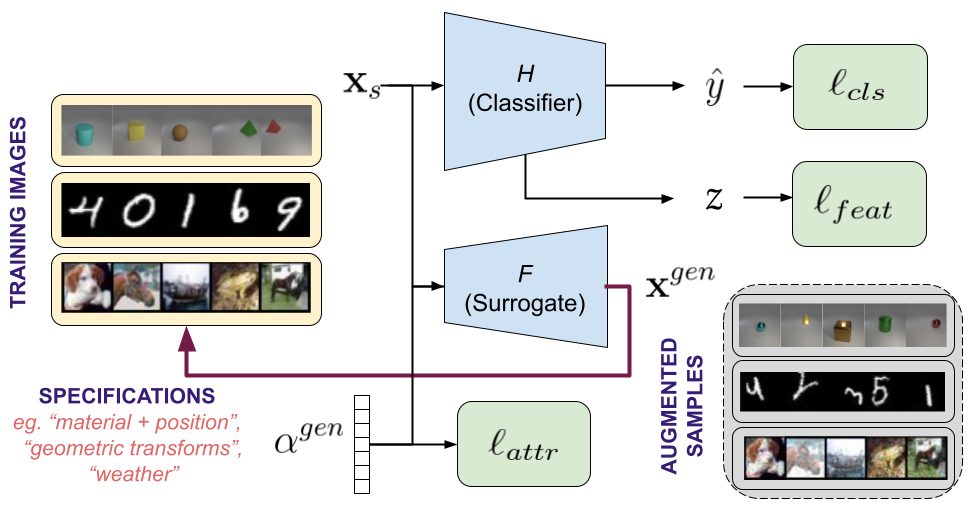
Tejas Gokhale, Rushil Anirudh, Bhavya Kailkhura, Jayaraman J. Thiagarajan, Chitta Baral, Yezhou Yang
pdf code
An adversarial training approach which learns to generate new samples so as to maximize exposure of the classifier to attributes-space. Studies robustness to semantic shifts that are beyond L-p norm perturbations, on 3 types of naturally occurring perturbations — object-related shifts, geometric transformations, and common image corruptions.
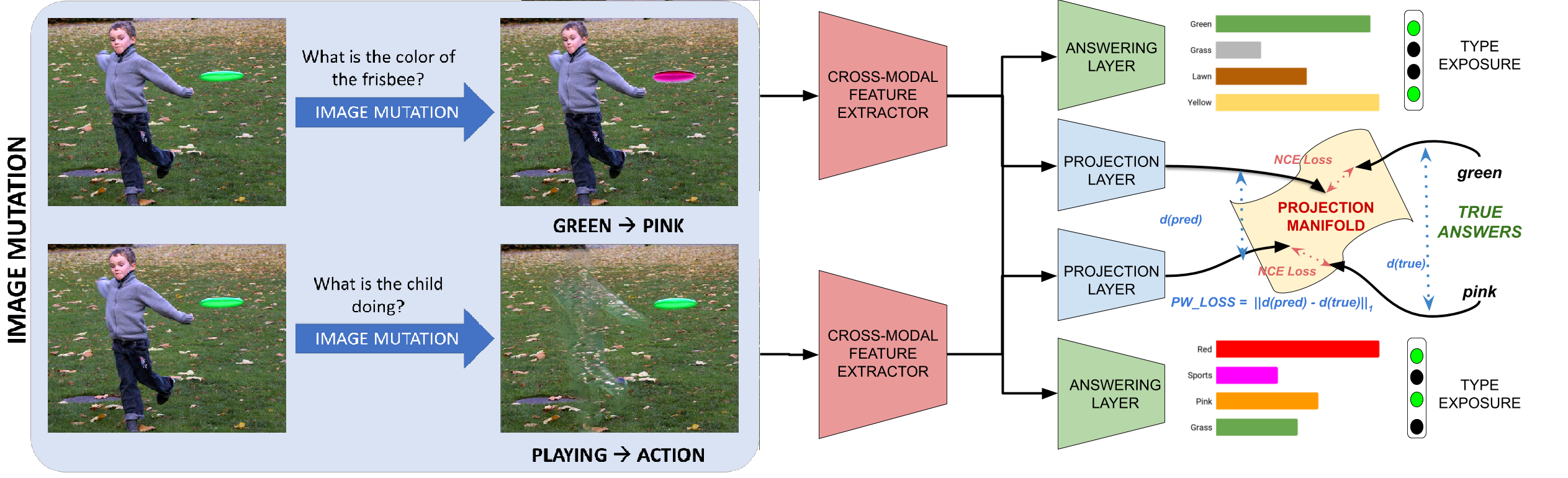
Tejas Gokhale, Pratyay Banerjee, Chitta Baral, Yezhou Yang
pdf data
MUTANT is a training paradigm that exposes VQA models to perceptually similar, yet semantically distinct mutations of the input image or question. We use a pairwise consistency loss between answers to original and mutant inputs as a regularization, along with an answer embedding NCE loss. MUTANTimproves generalization of VQA models under Changing Priors.

Zhiyuan Fang* Tejas Gokhale, Pratyay Banerjee, Chitta Baral, Yezhou Yang
pdf code web
Actions in videos are inherently linked to latent social and commonsense aspects. We present the first work on generating commonsense captions directly from videos, to describe latent intentions, attributes, and effects of humans in videos. Additionally we explore the use of open-ended video-based commonsense question answering (V2C-QA) as a way to enrich our captions.
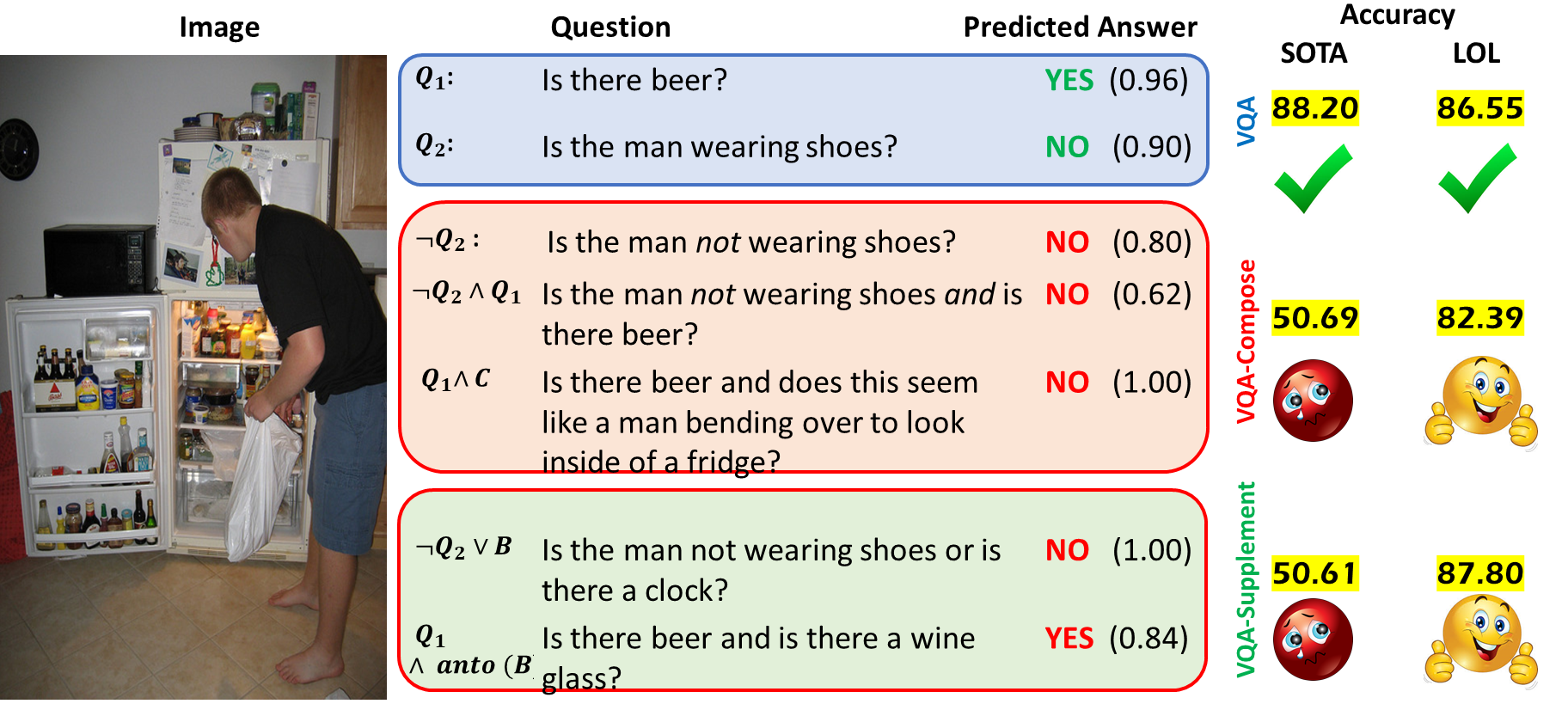
Tejas Gokhale, Pratyay Banerjee, Chitta Baral, Yezhou Yang
pdf, code data web video
VQA models struggle at negation, antonyms, conjunction, disjunction! We show a capability of answering logically composed questions with our novel modules and datasets, while retaining performance on VQA data.
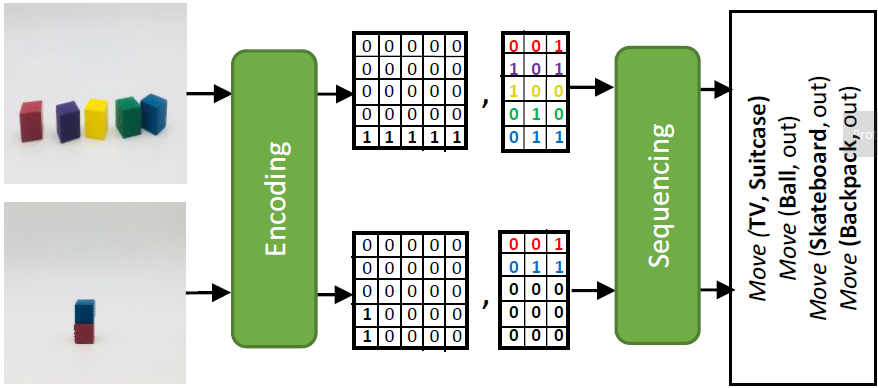
Tejas Gokhale, Shailaja Sampat, Zhiyuan Fang, Yezhou Yang, Chitta Baral,
pdf, [CVPR-VMC Paper] code web
Given two images (source, target) with different object configurations, what is the sequence of steps to re-arrange source to match target? For this reasoning task, our modular approach that contains a visual encoder and an event-sequencer/planner, and exhibits inductive generalization.
Books

Man Luo, Tejas Gokhale, Yezhou Yang, Chitta Baral
web
A comprehensive overview of the state-of-the-art methods in multimodal retrieval, generation, and retrieval-augmented generation.
Series Title: Synthesis Lectures on Computer Vision
Hardcover ISBN: 978-3-031-57816-8; Softcover ISBN978-3-031-57818-2; eBook ISBN: 978-3-031-57816-8
SUPPORT / SPONSORS
Cognitive Vision Group
 Sourajit Saha
Sourajit Saha Ziwei Zhang
Ziwei Zhang Shivanand Kundargi
Shivanand Kundargi Dylan Lang
Dylan Lang Naren Sivakumar
Naren Sivakumar Joey Mule
Joey Mule
Research Assistant
 Alexander Haibel
Alexander Haibel Arunabh Ramesh
Arunabh Ramesh- Nicholas Harrell, B.S. CE, UMBC 2025
- Alexander Shaner (Independent Study), B.S. CS, UMBC 2025
- Neel Patel (Research); M.S. CS, UMBC 2025
- Varun Magotra (Independent Study), B.S. CS, UMBC 2025
{kind=link}
List of All Collaborators
-
(chronological, affiliation at the time of collaboration)
- Aswin Sankaranarayanan, CMU
- Kuldeep Kulkarni, CMU
- Yezhou Yang, ASU
- Chitta Baral, ASU
- Pavan Turaga, ASU
- Rajhans Singh, ASU
- Shailaja Sampat, ASU
- Zhiyuan Fang, ASU
- Pratyay Banerjee, ASU
- Rushil Anirudh, LLNL
- Jay Thiagarajan, LLNL
- Bhavya Kailkhura, LLNL
- Abhishek Chaudhary, ASU
- Neeraj Varshney, ASU
- Swaroop Mishra, ASU
- Man Luo, ASU
- Bhavdeep Singh Sachdeva, ASU
- Yiran Luo, ASU
- Arindam Mitra, Microsoft Research
- Josh Feinglass, ASU
- Maitreya Patel, ASU
- Hamid Palangi, Microsoft Research
- Besa Nushi, Microsoft Research
- Vibhav Vineet, Microsoft Research
- Eric Horvitz, Microsoft Research
- Ece Kamar, Microsoft Research
- Sheng Cheng, ASU
- Ethan Wisdom, ASU
- Chaowei Xiao, ASU
- Agneet Chatterjee, ASU
- Sourajit Saha, UMBC
- Gabriela Ben Melech Stan, Intel
- Estelle Aflalo, Intel
- Vasudev Lal, Intel
- Sayak Paul, Huggingface
- Dhruba Ghosh, University of Washington
- Ludwig Schmidt, University of Washington
- Hannaneh Hajishirzi, University of Washington
- Abhiram Kusumba, ASU
- Changhoon Kim, Amazon
- Nilay Yilmaz, ASU
- Suren Jayasuriya, ASU
- Naresh Kumar Devulapally, University of Buffalo
- Vishnu Suresh Lokhande, University of Buffalo
- Shruti Agarwal, Adobe Research
- Shivanand Kundargi, UMBC
- Kowshik Thopalli, LLNL
- Jessica Sutton, NASA Goddard / UMBC
- Thomas Stanley, NASA Goddard / UMBC
- Hadi Jamali-Rad, Shell / TU Delft
- Sarah Rastegar, TU Delft
- Violeta Chatalbasheva, TU Delft
- Sieger Falkena, TU Delft
- Anuj Singh, TU Delft
- Yanbo Wang, TU Delft
Website theme inspirations: Alane Suhr, Stephen MacNeil, Jon Barron